
In this tutorial you will learn how to implement a simple network protocol using libdill.
The source code for individual steps of this tutorial can be found in tutorial/protocol subdirectory.
Handles are libdill's equivalent of file descriptors. A socket implementing our protocol will be pointed to by a handle. Therefore, we have to learn how to create custom handle types.
Standard include file for libdill is libdill.h. In this case, however, we will include libdillimpl.h which defines all the functions libdill.h does but also adds some extra stuff that can be used to implement different plugins to libdill, such as new handle types or new socket types:
#include <libdillimpl.h>To make it clear what API we are trying to implement, let's start with a simple test program. We'll call our protocol quux and at this point we will just open and close the handle:
int main(void) {
int h = quux_open();
assert(h >= 0);
int rc = hclose(h);
assert(rc == 0);
return 0;
}To start with the implementation we need a structure to hold data for the handle. At the moment it will contain only handle's virtual function table:
struct quux {
struct hvfs hvfs;
};Let's add forward declarations for functions that will be filled into the virtual function table. We'll learn what each of them is good for shortly:
static void *quux_hquery(struct hvfs *hvfs, const void *id);
static void quux_hclose(struct hvfs *hvfs);The quux_open function itself won't do much except for allocating the object, filling in the table of virtual functions and registering it with libdill runtime:
int quux_open(void) {
int err;
struct quux *self = malloc(sizeof(struct quux));
if(!self) {err = ENOMEM; goto error1;}
self->hvfs.query = quux_hquery;
self->hvfs.close = quux_hclose;
int h = hmake(&self->hvfs);
if(h < 0) {err = errno; goto error2;}
return h;
error2:
free(self);
error1:
errno = err;
return -1;
}Function hmake() does the trick. You pass it a virtual function table and it returns a handle. When the standard function like hclose() is called on the handle libdill will forward the call to the corresponding virtual function, in this particular case to quux_hclose(). The interesting part is that the first argument to the virtual function is no longer the handle but rather pointer to the virtual function table. And given that virtual function table is a member of struct quux it's easy to convert it to the pointer to the quux object itself.
quux_hclose() virtual function will deallocate the quux object:
static void quux_hclose(struct hvfs *hvfs) {
struct quux *self = (struct quux*)hvfs;
free(self);
}At the moment we can just return ENOTSUP from the other two virtual functions.
Compile the file and run it to test whether it works as expected:
$ gcc -o step1 step1.c -ldillConsider a UDP socket. It is actually multiple things. It's a handle and as such it exposes functions like hclose(). It's a message socket and as such it exposes functions like msend() and mrecv(). It's also a UDP socket per se and as such it exposes functions like udp_send() or udp_recv().
libdill provides an extremely generic mechanism to address this multi-faceted nature of handles. In fact, the mechanism is so generic that it's almost silly. There's a hquery() function which takes ID as an argument and returns a void pointer. No assumptions are made about the nature of the ID or nature of the returned pointer. Everything is completely opaque.
To see how that can be useful let's implement a new quux function.
First, we have to define an ID for quux object type. Now, this may be a bit confusing, but the ID is actually a void pointer. The advantage of using a pointer as an ID is that if it was an integer you would have to worry about ID collisions, especially if you defined IDs in different libraries that were then linked together. With pointers there's no such problem. You can take a pointer to a global variable and it is guaranteed to be unique as two pieces of data can't live at the same memory location.
static const int quux_type_placeholder = 0;
static const void *quux_type = &quux_type_placeholder;Second, let's implement hquery() virtual function, empty implementation of which has been created in previous step of this tutorial:
static void *quux_hquery(struct hvfs *hvfs, const void *type) {
struct quux *self = (struct quux*)hvfs;
if(type == quux_type) return self;
errno = ENOTSUP;
return NULL;
}To understand what this is good for think of it from user's perspective: You call hquery() function and pass it a handle and the ID of quux handle type. The function will fail with ENOTSUP if the handle is not a quux handle. It will return pointer to quux structure if it is. You can use the returned pointer to perform useful work on the object.
But wait! Doesn't that break encapsulation? Anyone can call hquery() function, get the pointer to raw quux object and mess with it in unforeseen ways.
But no. Note that quux_type is defined as static. The ID is not available anywhere except in the file that implements quux handle. No external code will be able to get the raw object pointer. The encapsulation works as expected after all.
All that being said, we can finally implement our new user-facing function:
int quux_frobnicate(int h) {
struct quux *self = hquery(h, quux_type);
if(!self) return -1;
printf("Kilroy was here!\n");
return 0;
}Modify the test to call the new function, compile it and run it:
int main(void) {
...
int rc = quux_frobnicate(h);
assert(rc == 0);
...
}Let's turn the quux handle that we have implemented into quux network socket now.
We won't implement the entire network stack from scratch. The user will layer the quux socket on top of an existing bytestream protocol, such as TCP. The layering will be done via quux_attach() and quux_detach() functions.
In the test program we are going to layer quux protocol on top of ipc protocol (UNIX domain sockets):
coroutine void client(int s) {
int q = quux_attach(s);
assert(q >= 0);
/* Do something useful here! */
s = quux_detach(q);
assert(s >= 0);
int rc = hclose(s);
assert(rc == 0);
}
int main(void) {
int ss[2];
int rc = ipc_pair(ss);
assert(rc == 0);
go(client(ss[0]));
int q = quux_attach(ss[1]);
assert(q >= 0);
/* Do something useful here! */
int s = quux_detach(q);
assert(s >= 0);
rc = hclose(s);
assert(rc == 0);
return 0;
}To implement it the socket first need to remember the handle of the underlying protocol so that it can use it when sending and receiving data:
struct quux {
...
int u;
};To accomodate libdill's naming conventions for protocols running on top of other protocols, we have to rename quux_open() to quux_attach(). Attach function will accept a handle of the underlying bytestream protocol and create quux protocol on top of it:
int quux_attach(int u) {
int err;
struct quux *self = malloc(sizeof(struct quux));
if(!self) {err = ENOMEM; goto error1;}
self->hvfs.query = quux_hquery;
self->hvfs.close = quux_hclose;
self->hvfs.done = quux_hdone;
self->u = hown(u);
int h = hmake(&self->hvfs);
if(h < 0) {int err = errno; goto error2;}
return h;
error2:
free(self);
error1:
errno = err;
return -1;
}Note gow hown function is used to take ownership of the underlying socket. hown will give it a new handle number, thus making the old handle number owned by the caller unusable.
We can reuse quux_frobnicate and rename it to quux_detach. It will terminate the quux protocol and return the handle of the underlying protocol:
int quux_detach(int h) {
struct quux *self = hquery(h, quux_type);
if(!self) return -1;
int u = self->u;
free(self);
return u;
}libdill recognizes two kinds of network sockets: bytestream sockets and messages sockets. The main difference between the two is that the latter preserves the message boundaries while the former does not.
Let's say quux will be a message-based protocol. As such, it should expose functions like msend and mrecv to the user.
Do you remember the trick with adding new function to a handle? If not so, re-read step 2 of this tutorial. For adding message socket functions to quux we'll use the same mechanism except that instead of defining our own type ID we will use an existing one (msock_type) defined by libdill. Passing msock_type to hquery function will return pointer to a virtual function table of type msock_vfs. The table is once again defined by libdill:
struct msock_vfs {
int (*msendl)(struct msock_vfs *vfs,
struct iolist *first, struct iolist *last, int64_t deadline);
ssize_t (*mrecvl)(struct msock_vfs *vfs,
struct iolist *first, struct iolist *last, int64_t deadline);
};To implement the functions, we have to first add the virtual function table to quux socket object:
struct quux {
struct hvfs hvfs;
struct msock_vfs mvfs;
int u;
};We'll need forward declarations for msock functions:
static int quux_msendl(struct msock_vfs *mvfs,
struct iolist *first, struct iolist *last, int64_t deadline);
static ssize_t quux_mrecvl(struct msock_vfs *mvfs,
struct iolist *first, struct iolist *last, int64_t deadline);And we have to fill in the virtual function table inside quux_attach() function:
int quux_attach(int u) {
...
self->mvfs.msendl = quux_msendl;
self->mvfs.mrecvl = quux_mrecvl;
...
}Return the pointer to the msock virtual function table when hquery() is called with msock_type type ID:
static void *quux_hquery(struct hvfs *hvfs, const void *type) {
struct quux *self = (struct quux*)hvfs;
if(type == msock_type) return &self->mvfs;
if(type == quux_type) return self;
errno = ENOTSUP;
return NULL;
}Note that quux_msendl() and quux_mrecvl() receive pointer to msock virtual function table which is not the same as the pointer to quux object. We'll have to convert it. To make that easier let's define this handy macro. It will convert pointer to an embedded structure to a pointer of the enclosing structure:
#define cont(ptr, type, member) \
((type*)(((char*) ptr) - offsetof(type, member)))Using the cont macro we can convert the mvfs into pointer to quux object. Here, for instance, is a stub implementation of quux_msendl() function:
static int quux_msendl(struct msock_vfs *mvfs,
struct iolist *first, struct iolist *last, int64_t deadline) {
struct quux *self = cont(mvfs, struct quux, mvfs);
errno = ENOTSUP;
return -1;
}Add a similar stub implementation for quux_mrecvl() function and proceed to the next step.
Now that we've spent previous four steps doing boring scaffolding work we can finally do some fun protocol stuff.
Modify the client part of the test program to send a simple text message:
coroutine void client(int s) {
...
int rc = msend(q, "Hello, world!", 13, -1);
assert(rc == 0);
...
}Function msend will forward the call to our quux_msendl() stub function which, at the moment, does nothing but returns ENOTSUP error. To implement it we have to decide how the quux network protocol will actually look like.
Let's say it will prefix individual messages with 8-bit size. The test message from above is going to look like this on the wire:
Given that size field is a single byte messages can be at most 255 bytes long. That may be a problem in the real world but this is just a tutorial so let's ignore it and move on.
Note that payload data is passed to the quux_msendl() function in form of two pointers to a structure called iolist.
Iolists are libdill's alternative to POSIX iovecs. Where iovecs are arrays of buffers (so called scatter/gather arrays) iolists are linked lists of buffers. Very much like iovec, iolist has iol_base pointer pointing to the data and iol_len field containing the size of the data. Unlike iovec though it has also iol_next field which points to the next buffer in the list. iol_next of the last item in the list is set to NULL.
An iolist instance may look like this:
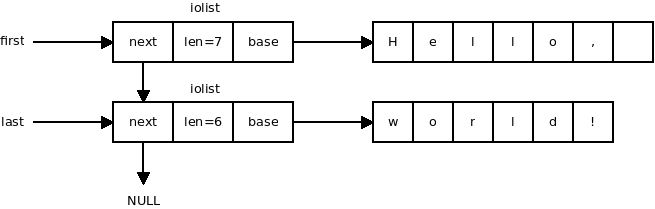
Don't forget that there's an extra field in iolist, one called iol_rsvd, which should be always set to zero.
Given that we decided to prefix quux messages with message size we have to compute the message size first. We can do so by iterating over the iolist and summing all the buffer sizes. If size is greater than 254 (we'll use number 255 for a special purpose later on) it's an error.
size_t sz = 0;
struct iolist *it;
for(it = first; it; it = it->iol_next)
sz += it->iol_len;
if(sz > 254) {errno = EMSGSIZE; return -1;}Now we can send the size and the payload to the underlying socket:
uint8_t c = (uint8_t)sz;
int rc = bsend(self->u, &c, 1, deadline);
if(rc < 0) return -1;
rc = bsendl(self->u, first, last, deadline);
if(rc < 0) return -1;To indicate success return zero from the function. Then compile and test.
However, let's suppose we want to implement a high-performance protocol. Looking at the code, it's not hard to spot that there's quite a serious performance problem: For each message, the underlying network stack is traversed twice, one for the size byte, second time for the payload. Instead of doing two send calls and traversing the underlying network stack twice we can modify the iolist to include the size byte as well as the payload and send the entire message using a single bsendl() call. The modified iolist may look as follows. Grey parts are the original iolist as passed to quux_msendl() by the user. Black part is the modification done inside quux_msendl():
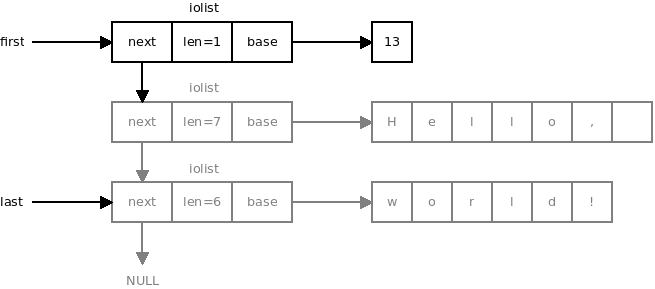
The code will look like this:
uint8_t c = (uint8_t)sz;
struct iolist hdr = {&c, 1, first, 0};
int rc = bsendl(self->u, &hdr, last, deadline);
if(rc < 0) return -1;Add the lines to receive a message to the test. Note that mrecvl() function returns size of the message:
int main(void) {
...
char buf[256];
ssize_t sz = mrecv(q, buf, sizeof(buf), -1);
assert(sz >= 0);
printf("%.*s\n", (int)sz, buf);
...
}To implement the receive function we'll have to read the 8-bit size first:
uint8_t sz;
int rc = brecv(self->u, &sz, 1, deadline);
if(rc < 0) return -1;Great. Now we know that the message is sz bytes long. We are going to read those bytes into user's buffers. But let's take care of one special case first.
libdill allows iolist passed to the receive function to be NULL. What that means is that the user wants to skip a message. This can be easily done given that the underlying protocol provides similar skipping functionality:
if(!first) {
rc = brecv(self->u, NULL, sz, deadline);
if(rc < 0) return -1;
return sz;
}If the iolist is not NULL we will find out the overall size of the buffer and check whether message will fit into it:
size_t bufsz = 0;
struct iolist *it;
for(it = first; it; it = it->iol_next)
bufsz += it->iol_len;
if(bufsz < sz) {errno = EMSGSIZE; return -1;}It the message fits into the buffer payload can be received:
size_t rmn = sz;
for(it = first; it; it = it->iol_next) {
size_t torecv = rmn < it->iol_len ? rmn : it->iol_len;
rc = brecv(self->u, it->iol_base, torecv, deadline);
if(rc < 0) return -1;
rmn -= torecv;
if(rmn == 0) break;
}
return sz;We are facing the same performance problem here as we did in the send function. Calling brecv() multiple times means extra network stack traversals and thus decreased performance. And we can apply a similar solution. We can modify the iolist in such a way that it can be simply forwarded to the underlying socket.
The main problem in this case is that the size of the message may not match the size of the buffer supplied by the user. If message is larger than the buffer we will simply return an error. However, if message is smaller than the buffer there's a problem. Bytestream's brecvl() function has no size argument. It just receives data until the buffer is completely full. Therefore, we will have to shrink the buffer to match the message size.
Let's say the iolist supplied by the user looks like this:
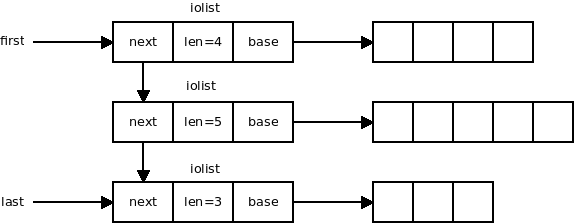
If the message is 5 bytes long we are going to modify the iolist like this. Grey parts are the iolist structures passed to quux socket by the user. Black parts are the modifications:
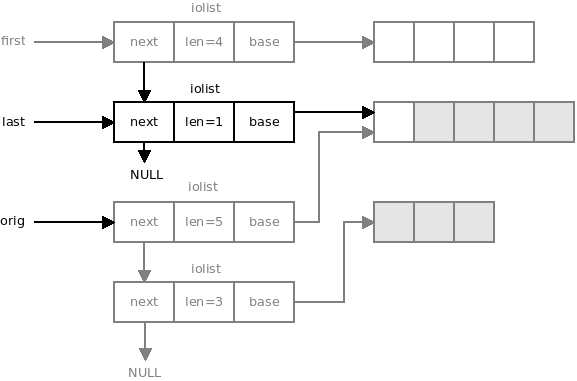
In iolist-based functions the list is supposed to be unchanged when the function returns. However, it can be temporarily modified while the function is in progress. Therefore, iolists are not guaranteed to be thread- or coroutine-safe.
We are modifying the iolist here, which is all right, but we have to make sure to revert all our changes before the function returns. Note the orig pointer in the above diagram. It won't be passed to the underlying socket. Instead, it will be used to restore the original iolist after sending is done.
The code for the above looks like this:
size_t rmn = sz;
it = first;
while(1) {
if(it->iol_len >= rmn) break;
rmn -= it->iol_len;
it = it->iol_next;
if(!it) {errno = EMSGSIZE; return -1;}
}
struct iolist orig = *it;
it->iol_len = rmn;
it->iol_next = NULL;
rc = brecvl(self->u, first, last, deadline);
*it = orig;
if(rc < 0) return -1;
return sz;Compile and run!
Consider the following scenario: User wants to receive a message. The message is 200 bytes long. However, after reading 100 bytes, receive function times out. That puts you, as the protocol implementor, into an unconfortable position. There's no way to push the 100 bytes that were already received back to the underlying socket. libdill sockets provide no API for that, but even in principle, it would mean that the underlying socket would need an unlimited buffer in case the user wanted to push back one terrabyte of data.
libdill solves this problem by not trying too hard to recover from errors, even from seemingly recoverable ones like ETIMEOUT.
When building on top of a bytestream protocol -- which in unrecoverable by definition -- you thus have to track failures and once error happens return an error for any subsequent attampts to receive a message. And same reasoning and same solution applies to outbound messages.
Note that this does not apply when you are building on top of a message socket. Message sockets may be recoverable. Consider UDP. If receiving one packet fails you can still receive the next packet.
Anyway, to implement error handling in quux protocol, let's add two booleans to the socket to track whether sending/receiving had failed already:
struct quux {
...
int senderr;
int recverr;
};Initialize them to false in quux_attach() function:
self->senderr = 0;
self->recverr = 0;Set senderr to true every time when sending fails and recverr to true every time when receiving fails. For example:
if(sz > 254) {self->senderr = 1; errno = EMSGSIZE; return -1;}Finally, fail send and receive function if the error flag is set:
static int quux_msendl(struct msock_vfs *mvfs,
struct iolist *first, struct iolist *last, int64_t deadline) {
struct quux *self = cont(mvfs, struct quux, mvfs);
if(self->senderr) {errno = ECONNRESET; return -1;}
...
}
static ssize_t quux_mrecvl(struct msock_vfs *mvfs,
struct iolist *first, struct iolist *last, int64_t deadline) {
struct quux *self = cont(mvfs, struct quux, mvfs);
if(self->recverr) {errno = ECONNRESET; return -1;}
...
}Let's say we want to support mutliple versions of quux protocol. When a quux connection is established peers will exchange their version numbers and if those don't match, protocol initialization will fail.
In fact, we don't even need proper handshake. Each peer can simply send its version number and wait for version number from the other party. We'll do this work in quux_attach() function.
Given that sending and receiving are blocking operations quux_attach() will become a blocking operation itself and will accept a deadline parameter:
int quux_attach(int u, int64_t deadline) {
...
const int8_t local_version = 1;
int rc = bsend(u, &local_version, 1, deadline);
if(rc < 0) {err = errno; goto error2;}
uint8_t remote_version;
rc = brecv(u, &remote_version, 1, deadline);
if(rc < 0) {err = errno; goto error2;}
if(remote_version != local_version) {err = EPROTO; goto error2;}
...
error2:
free(self);
error1:
hclose(u);
errno = err;
return -1;
}Note how failure of initial handshake not only prevents initialization of quux socket, it also closes the underlying socket. This is necessary because otherwise the underlying sockets will be left in undefined state, with just half of quux handshake being done.
Modify the test program accordingly (add deadlines), compile and test.
Imagine that user wants to close the quux protocol and start a new protocol, say HTTP, on top of the same underlying TCP connection. For that to work both peers would have to make sure that they've received all quux-related data before proceeding. If they had left any unconsumed data in TCP buffers, the subsequent HTTP protocol would read it and get confused by it.
To achieve that the peers will send a single termination byte (255) each to another to mark the end of the stream of quux messages. After doing so they will read any receive and drop all quux messages from the peer until they receive the 255 byte. At that point all the quux data are cleaned up, both peers have consistent view of the world and HTTP protocol can be safely initiated.
Let's start with addinbg two flags to the quux socket object, one meaning "termination byte was already sent", the other "termination byte was already received":
struct quux {
...
int senddone;
int recvdone;
};The flags have to be initialized in the quux_attach() function:
int quux_attach(int u, int64_t deadline) {
...
self->senddone = 0;
self->recvdone = 0;
...
}If termination byte was already sent send function should return EPIPE error:
static int quux_msendl(struct msock_vfs *mvfs,
struct iolist *first, struct iolist *last, int64_t deadline) {
...
if(self->senddone) {errno = EPIPE; return -1;}
...
}If termination byte was already received receive function should return EPIPE error. Also, we should handle the case when termination byte is received from the peer:
static ssize_t quux_mrecvl(struct msock_vfs *mvfs,
struct iolist *first, struct iolist *last, int64_t deadline) {
...
if(self->recvdone) {errno = EPIPE; return -1;}
...
if(sz == 255) {self->recvdone = 1; errno = EPIPE; return -1;}
...
}quux_done function will start the terminal handshake. However, it is not supposed to wait till it is finished. The semantics of the done function are "user is not going to send any more data". You can think of it as of EOF marker of a kind.
int quux_done(int h, int64_t deadline) {
struct quux *self = hquery(h, quux_type);
if(!self) return -1;
if(self->senddone) {errno = EPIPE; return -1;}
if(self->senderr) {errno = ECONNRESET; return -1;}
uint8_t c = 255;
int rc = bsend(self->u, &c, 1, deadline);
if(rc < 0) {self->senderr = 1; return -1;}
self->senddone = 1;
return 0;
}At this point we can modify quux_detach() function so that it properly cleans up any leftover protocol data.
First, it will send the termination byte if it was not already sent. Then it will receive and drop messages until it receives the termination byte:
int quux_detach(int h, int64_t deadline) {
int err;
struct quux *self = hquery(h, quux_type);
if(!self) return -1;
if(self->senderr || self->recverr) {err = ECONNRESET; goto error;}
if(!self->senddone) {
int rc = quux_done(h, deadline);
if(rc < 0) {err = errno; goto error;}
}
while(1) {
ssize_t sz = quux_mrecvl(&self->mvfs, NULL, NULL, deadline);
if(sz < 0 && errno == EPIPE) break;
if(sz < 0) {err = errno; goto error;}
}
int u = self->u;
free(self);
return u;
error:
quux_hclose(&self->hvfs);
errno = err;
return -1;
}Note how the socket, including the underlying socket, is closed when the function fails.
Adjust the test, compile and run. You are done with the tutorial. Have fun writing your own network protocols!